
.png)
By now, we’ve defined what data modeling is and how to design scalable, high-performance architectures .
In this third and final part, we look forward to how modern data architectures and AI-integrated modeling are reshaping analytics, intelligence, and decision-making.
The new frontier of data modeling isn’t just about structure and performance. It’s about context, adaptability, and intelligence, creating systems that not only describe the past but also learn from it to predict what’s next. To learn more about the core concepts , techniques and best practises for Data Modeling visit the Ulitmate Guide to Data Modelling
Earlier in my career, I spent hours reconciling reports from different CRMs — each with its own definition of "revenue" or "active customers". Now at Databrain, I see how a Semantic Layer solves exactly that problem, bringing the alignment and clarity I once had to build manually.
Why Traditional Models Fall Short in an AI-Driven World
Traditional relational or dimensional models were built for a world where data was predictable, structured, and mostly batch processed. That world no longer exists.
At present, data flows continuously from sensors, APIs, customer interactions, and machine learning pipelines. It changes every second.
When teams rely on static data models, several problems surface:
- BI dashboards and ML systems pull from disconnected pipelines.
- Definitions drift between departments.
- Analysts and scientists duplicate effort building the same transformations.
- Governance often turns into a reaction fixing problems after they appear, instead of preventing them.
What’s needed now are data models that grow and adjust as the organization evolves frameworks that can support analytics and operations seamlessly, without breaking each time something changes.
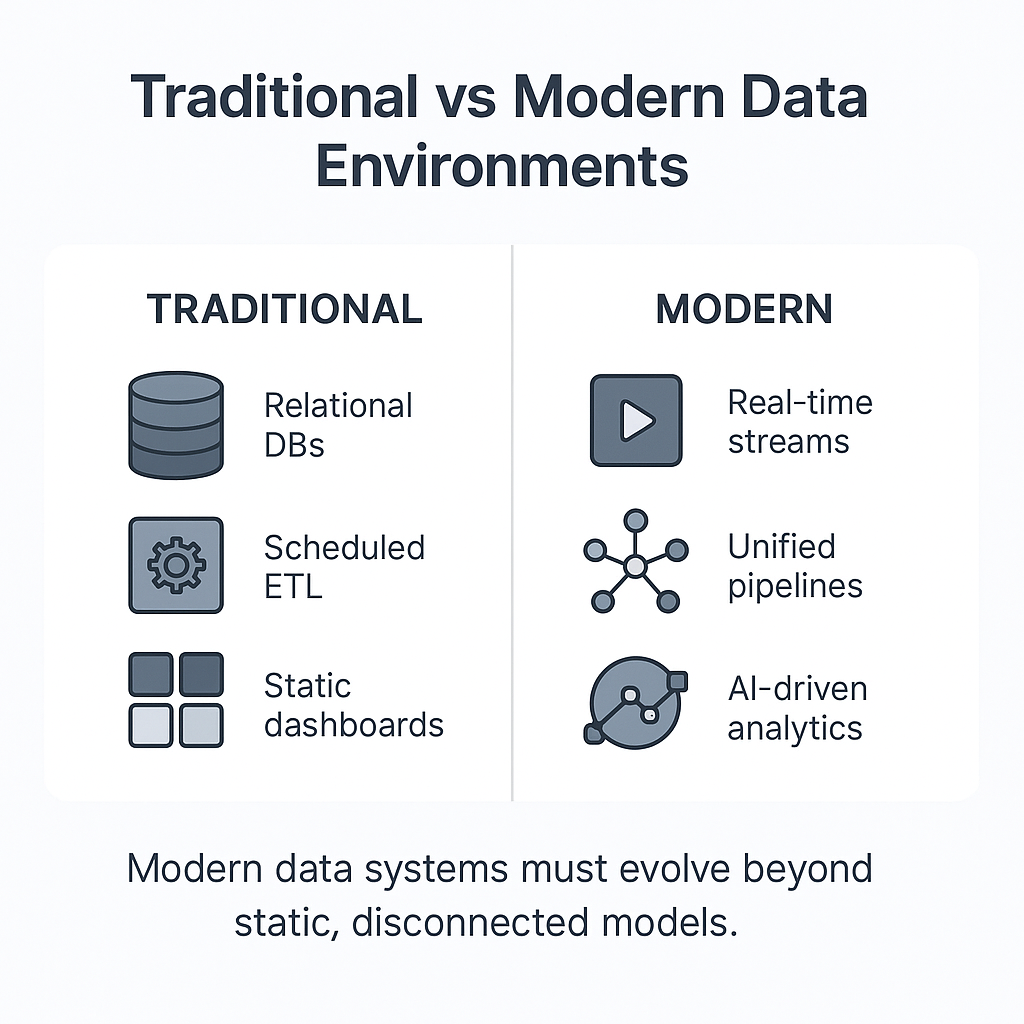
Inside the Modern Data Architecture
Leading platforms like AWS, IBM, and Microsoft describe a modern data architecture as a unified ecosystem where data flows freely and intelligently across ingestion, transformation, and insight layers.
Here’s what defines it:

- Data Access: Make data widely available while keeping it secure.
- Interoperability: Let cloud, hybrid, and on-prem systems talk to each other through open standards.
- Elastic Scalability: Expand compute or storage on demand, without interrupting work.
- Automation and Intelligence: Use ML to keep pipelines healthy and spot anomalies before they escalate.
- Governance and Trust: Trace lineage, maintain data quality, and meet compliance from the ground up.
- Real-Time Insight: Support streaming analytics that update as events happen.
These principles sound abstract, but in practice they shape the blueprints for every next-generation data platform being built today.
Key Frameworks Shaping Modern Data Systems
Lakehouse Architecture
A Lakehouse blends the openness of a data lake with the order and dependability of a warehouse. Teams can work with structured, semi-structured, or unstructured data, all in one place whether they’re building dashboards or training ML models.
Why does it matter?
- One storage and compute layer for BI and ML.
- ACID transactions ensure consistency.
- Open formats like Delta, Iceberg, and Hudi promote interoperability.
Example:
A retail company might use a Lakehouse to train an ML model for demand forecasting and power executive dashboards using the same dataset — removing redundant ETL processes entirely.
Data Mesh
A Data Mesh redefines how organizations manage data.
Instead of one central team owning all pipelines, each business domain owns its own data product — complete with quality metrics, governance, and APIs. It’s not about decentralization for its own sake, but about aligning ownership with expertise.
When sales teams manage sales data and finance manages revenue data, accuracy and accountability increase naturally.
This model scales organizationally, ensuring that insights stay close to where business value is created, without losing governance or consistency.
Lambda Architecture
The Lambda Architecture combines speed and reliability.
It uses two layers to handle data at different velocities:
- A batch layer for long-term, accurate storage and computation.
- A speed layer for low-latency, real-time updates.
Example:
A fintech company might process historical transaction data in the batch layer for compliance reports, while using the speed layer to flag fraud within seconds.
Kappa Architecture
The Kappa Architecture simplifies Lambda by treating all data as a continuous stream — no separate batch layer.
Historical data can be replayed as events, allowing real-time and historical analytics to run on the same framework.
Example:
A logistics platform could stream vehicle telemetry data to monitor route performance in real time, while simultaneously replaying historical route data to optimize fuel usage within the same streaming model.
When combined, these frameworks form the backbone of modern data systems that balance structure and flexibility to power real-time dashboards, predictions, and intelligent applications, all from the same foundation.
From Data Models to Intelligent Models: ML-Integrated Modeling
As organizations embed machine learning deeper into their workflows, data modeling is evolving from schema design to feature design.
Models aren’t just diagrams anymore; they represent live, learning systems that respond to context.
Here’s what that involves:
- Feature Alignment: Logical models surface reusable, business-ready features such as average order value, churn likelihood, or customer retention.
- Data Lineage: Each feature traces directly to its raw inputs, making every prediction and metric easy to explain.
- Schema Versioning: Training and inference workflows use synchronized dataset versions.
- Hybrid Storage: Real-time feature stores like Redis or Feast work in sync with analytical stores such as Snowflake or Databricks.
- Connected Governance: BI metrics and ML features share a single semantic layer to reduce drift and redundancy.
The payoff:
When definitions stay consistent, trust follows. A metric like active_user_30d should have the same meaning whether it’s used in a dashboard or in a machine learning model.
AI-Assisted Data Modeling: The New Co-Pilot for Analysts
Artificial intelligence is reshaping the daily work of modeling. Tasks that once took hours of manual setup can now be automated, guided, or even suggested by the modern modeling tools themselves.
AI-enabled tools can:
- Auto-generate entity-relationship diagrams from source data.
- Suggest joins and constraints based on existing query patterns.
- Identify anomalies or redundant relationships.
- Recommend normalization or denormalization strategies.
- Generate documentation and lineage maps automatically.
These capabilities can significantly reduce modeling time often by more than half while improving overall model consistency.
The Unified Semantic Layer: Where BI Meets AI
A major step forward in today’s modeling landscape is the unified semantic layer, a central space that connects business terms, governance, and technical definitions.
Why this matters:
- Define metrics once, and use them everywhere in dashboards, APIs, or ML workflows.
- Give teams straightforward access while keeping governance intact.
- Ensure that every tool and system draws from the same shared definitions.
At Databrain, our semantic layer ensures exactly that. You can explore it here: Databrain Semantic Layer Documentation
Example:
If “Revenue by Active Customer” is defined once in the semantic layer, that definition automatically updates across both financial dashboards and predictive models — eliminating duplication and inconsistency.
A unified semantic layer brings order to complexity, ensuring analytics and AI share a single, governed truth.
Designing a Hybrid Data Architecture for BI + ML
Let’s bring it all together designing a hybrid ecosystem that unites BI dashboards and ML workflows under one architecture.
Layer 1: Ingestion
- Stream live data through Kafka, Kinesis, or Striim.
- Collect batches from SaaS apps, CRMs, or internal databases.
Layer 2: Storage (Lakehouse)
- Store raw, processed, and feature data in a unified Delta or Iceberg lake.
- Support a mix of structured tables and unstructured files.
Layer 3: Processing
- Transform data using Lambda or Kappa pipelines.
- Orchestrate transformations with Airflow or dbt.
Layer 4: Semantic & Governance Layer
- Define metrics once using dbt or Databrain’s semantic layer.
- Manage access and lineage through centralized policies.
Layer 5: Consumption
- Feed BI dashboards and ML feature stores from the same semantic layer.
- Continuously monitor performance, usage, and data drift.
This hybrid model ensures a single source of truth across analytics and AI where business questions and machine predictions are powered by the same trusted data.
The Role of Real-Time and Event-Driven Modeling
Businesses can no longer afford to look backward only. They need to understand what’s happening as it happens.
Event-driven modeling enables this responsiveness:
- Lambda and Kappa pipelines deliver insights with minimal latency.
- Graph and time-series databases capture relationships and trends instantly.
- Streaming semantic layers keep metrics fresh the moment events occur.
This shift turns analytics from static reporting into proactive intelligence where systems forecast, alert, and respond in real time.
The Future: Self-Evolving Data Models
We’re entering an era where data models will start adapting on their own.
Future systems will learn from their usage patterns and evolve automatically as the business changes.
We’re already seeing early signs:
- Schemas that adjust dynamically as data patterns shift.
- AI discovering new relationships between entities.
- Continuous optimization based on query and model performance.
- Unified representations merge structured and unstructured data seamlessly.
The data model of the future will be self-learning and continuously aligning itself with how people, systems, and decisions interact.
Connecting the Dots: From Concept to Intelligence
All are connect under The Ultimate Guide to Data Modeling: Concepts, Techniques, and Best Practices, a comprehensive reference for designing and future-proofing data systems that deliver true business insight.
Data modeling is the bridge between data and understanding. With AI, this bridge becomes intelligent as the one that learns, adapts, and refines itself over time. The goal is not to replace human decision-making but to enhance it with systems that understand business context, adapt to scale, and operate with intelligence.
At Databrain, we see this as the foundation of decision intelligence where analytics and AI share the same trusted backbone, and every model, metric, and insight speaks the same language.


