
.png)
Natural Language Analytics Isn’t Magic, It’s a Pipeline
Most people think NLQ is simple: type a question in English, get an answer. Anyone who has worked with real users and real data knows that’s not how it works. Teams evaluating NLQ often start with the question: “How does NLQ work?” and the answer requires understanding each stage of the pipeline.
Plain-language questions are vague. Schemas are messy. Metric definitions rarely match across teams.
So NLQ can’t just “translate text to SQL”. It has to understand intent, interpret business language, map it to the right tables, build safe joins, generate optimized SQL, and validate everything before execution.
If any step fails, the answer is wrong and trust evaporates. This article breaks down the actual pipeline behind NLQ, the parts most vendor blogs gloss over, and what it takes to make it reliable in real analytics environments.
What NLQ Actually Does Beyond "Rewrite English Into SQL"
Most articles frame NLQ as a simple NLP → SQL translation.
In reality, NLQ systems perform four core jobs:
- Understand the question (intent detection)
- Map language to data models (schema linking)
- Generate and optimize SQL
- Validate the query and ensure permission safety
Without all four, NLQ becomes a toy, accurate only when the question is obvious and the schema is tiny.
Why this matters
If your NLQ engine only “parses text” you’re not doing analytics.
The Full NLQ Pipeline (Step-by-Step)
Teams evaluating NLQ often start with the question: “How does NLQ work?” and the answer requires understanding each stage of the pipeline.
This section gives you the complete pipeline modern NLQ systems use, one that’s missing from 90% of the articles currently ranking for NLQ. This entire pipeline is what separates serious AI-powered analytics and natural language to SQL systems from the shallow “text-to-query” demos you see online.
Step 1: Intent Extraction
The engine breaks the question into:
- Query type: aggregated metric, comparison, filter, trend, ranking
- Action: calculate, compare, group, filter
- Time context: “this month”, “last quarter”, “over time”
Example:
Question: “How did MRR grow over the last 6 months by region?”
Intent: time-series trend + group by region
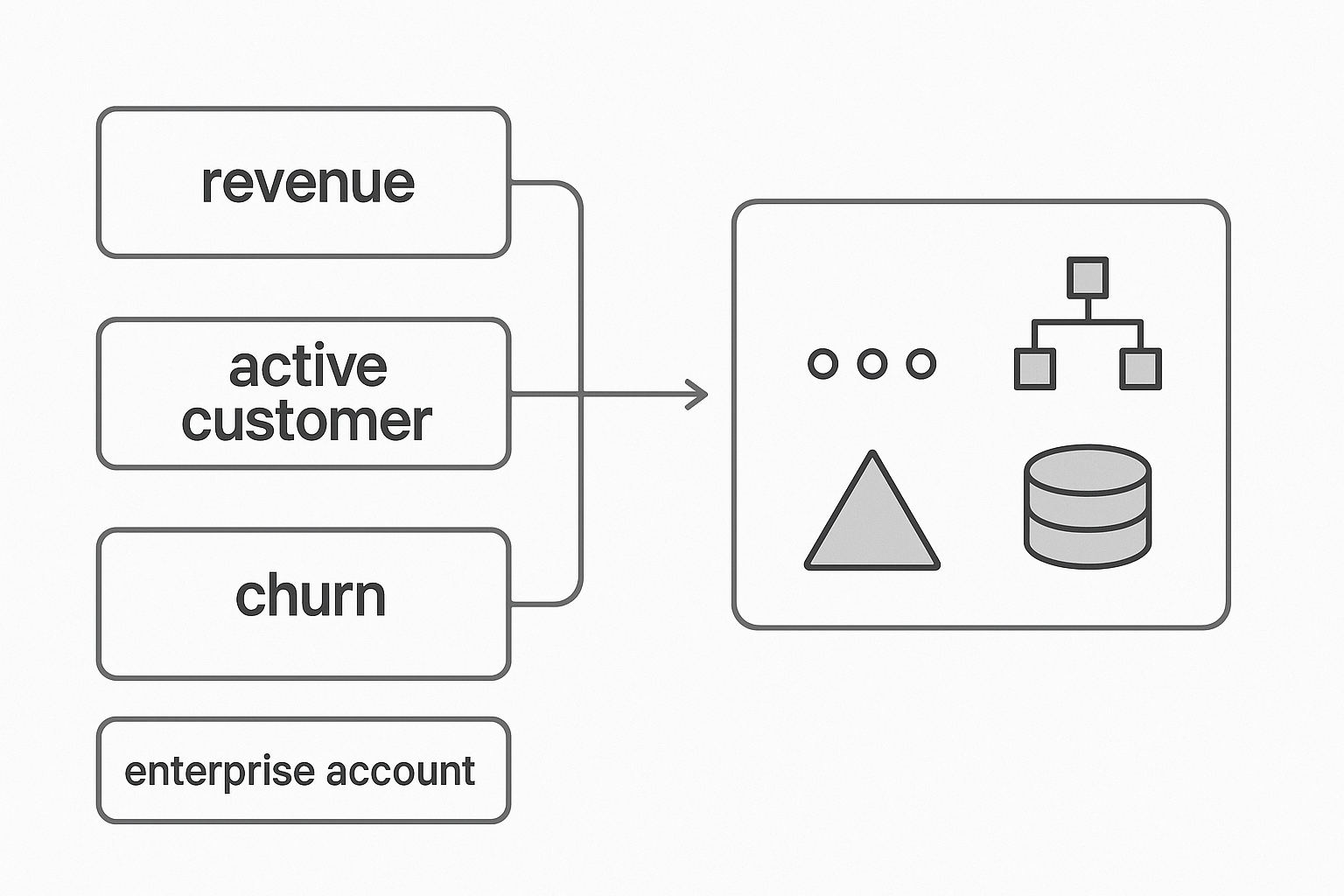
Step 2: Entity Mapping (Business Terms → Concepts)
This is where NLQ systems fail most often. Users don’t speak in column names.
They speak in concepts like:
- revenue
- active customer
- churn
- MRR
- enterprise account
- trial user
A strong NLQ engine resolves these to the right semantics.
Example:
“Active customers” → customers with at least one transaction in the last 30 days.
This mapping is defined once, reused everywhere, and enforced consistently. This is far beyond simple natural language to SQL translation.
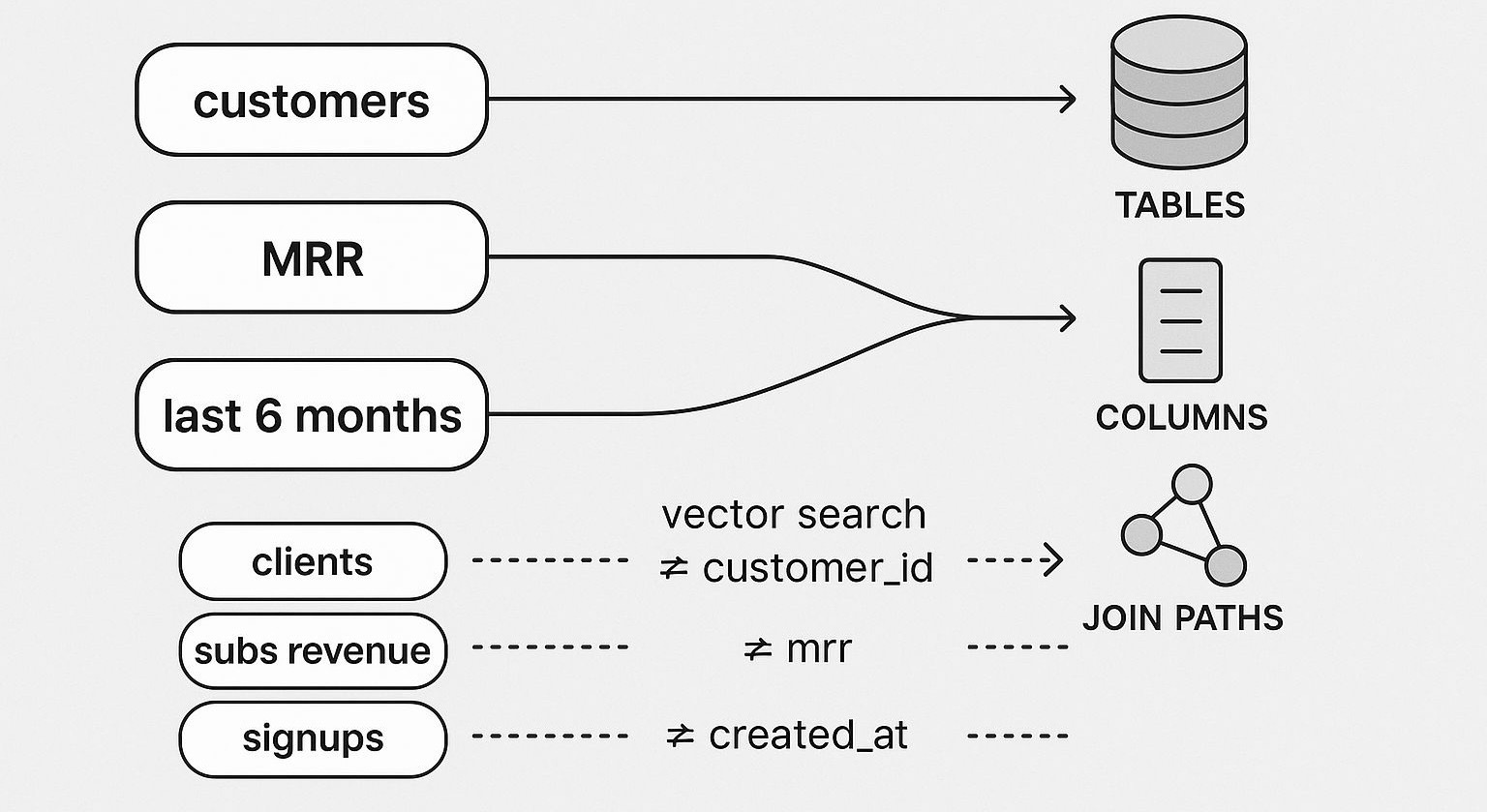
Step 3: Schema Linking (Language → Tables/Columns)
This is the hardest part of NLQ.
The engine must decide:
- Which table contains “customers”
- Where “MRR” lives
- Which date column refers to “last 6 months”
- And which join path connects everything
Vector search enhances this by matching synonyms:
- “clients” ≈ “customer_id”
- “subs revenue” ≈ “mrr”
- “signups” ≈ “created_at”
A good system also uses:
- primary/foreign key relationships
- semantic model relationships
- known join graphs
This is where legacy NLQ systems broke down (too literal, too fragile).
Step 4: Join Path Calculation
Once relevant columns are found, the system determines how they relate.
Example:
To answer “MRR by region” the engine must join:
subscriptions → customers → regions
A weak NLQ system:
- picks the wrong path
- joins too many tables
- creates Cartesian explosions
A strong system:
- uses semantic models
- validates graph structure
- prunes unnecessary joins
Step 5: SQL Generation
Once intent, entities, columns, and join paths are mapped, the system generates SQL.
A good NLQ engine:
- uses CTEs for readability
- pushes filters down
- applies GROUP BY intelligently
- handles “compare vs previous period” logic
- uses window functions when needed
Example output:
NLQ becomes a practical part of AI-powered analytics only when grounded in semantics.
Step 6: Validation & Rewriting
All modern NLQ engines must guard against:
- missing joins
- unusable filters
- unauthorized columns
- empty results
- ambiguous intent
Databrain’s validator checks:
- Is every column resolvable?
- Does the user have permission?
- Does the join path align with semantic rules?
- Are aggregates allowed on this metric?
If not, the engine automatically rewrites the query.
Handling Ambiguous Business Terms
In business data, terms sound simple but their meanings differ across teams, tools, and contexts. The problem isn't SQL or NLP, it's interpretation.
Example: Revenue isn’t one single number
When someone says “Revenue”, what exactly do they mean?
It could refer to:
- Recognized Revenue → revenue earned per accounting rules
- Billed Revenue → invoices raised, regardless of delivery
- Cash Collected → actual payments received
- Booked Revenue → value of signed contracts/POs
- Recurring Revenue (MRR/ARR) → subscription-based revenue
- Net Revenue → after refunds/discounts/credits
None of these are synonyms, each is a different metric.
So if a user asks:
"What is revenue this quarter?"
the system must know which type.
Ambiguity sources:
LLMs can interpret language, but they don’t know your internal definitions. If definitions aren't explicit, models make assumptions.
How ambiguity is actually solved
With a semantic layer, you explicitly define:
- what each metric means
- how it is calculated
- business rules & exclusions
- which tables/columns it maps to
- valid synonyms or aliases
So “revenue” is never guessed, it's selected from a predefined meaning.
Semantic layer solves:
- definitions
- grain
- relationships
- default filters
- safe aggregations
When semantic definitions exist, NLQ accuracy jumps from ~55% to 90%+.
Modern semantic layer NLQ engines rely on predefined metrics, relationships, and governed definitions to remove ambiguity.
Independent research backs this up, an AtScale/Dataversity study found that NLQ accuracy increases from ~20% without a semantic layer to 92.5% with one, proving how essential structured semantics are for reliable conversational analytics.
How Vector Search Improves Schema Matching
Vector embeddings encode:
- synonyms
- business context
- closeness
- categorical similarity
Examples:
- “ARR” sits close to “annual recurring revenue”
- “region_name” sits close to “geography”
- “signups” sits close to “new users”
This drastically improves accuracy in:
- wide schemas
- poorly named tables
- multi-source datasets
Why Semantic Models Change NLQ Accuracy Entirely
Vector search helps matching. LLMs help parsing. But semantic models guarantee correctness.
They provide:
- metrics with fixed formulas
- dimension relationships
- valid join paths
- default filters
- consistent time logic
This removes ambiguity so the engine never “guesses”
This is why Databrain supports NLQ at enterprise scale because the semantic layer is doing the heavy lifting.
Hard Truths About NLQ Systems
Let’s cut through the marketing:
Hard Truth 1:
If you rely on LLMs alone, your NLQ accuracy will tank. LLMs hallucinate joins. They don’t know your schema. They don’t understand business definitions.
State-of-the-art models like GPT-4o and Claude 3.5 struggle with schema-specific reasoning unless they're grounded in a semantic layer, which is why leading LLM analytics systems rely on structured metadata rather than generative models alone.
Hard Truth 2:
You’re overestimating how clear your internal metric definitions are. Most companies don’t even agree on what “revenue” means. Expecting NLQ to magically resolve that is delusional.
Hard Truth 3:
Your NLQ engine is only as good as your semantic model. No semantic layer = chaos. And chaos doesn’t scale.
Hard Truth 4:
If your NLQ system doesn’t validate SQL, you're one bad query from crashing your warehouse. Join explosions. Full table scans. Infinite date ranges. Modern NLQ must protect users from themselves.
Typical NLQ Failure Modes And How Modern Systems Prevent Them
These are the failure patterns legacy NLQ engines never solved:
1. Wrong table selected
Fix: Vector search + semantic mappings.
2. Wrong join path
Fix: Prebuilt semantic graph.
3. Wrong metric definition
Fix: Central metric store.
4. Incorrect aggregation
Fix: Semantic grain rules.
5. Unauthorized data leakage
Fix: Row/column-level access validation.
6. Overly literal parsing
Fix: LLM rewriting + grounding.
7. Poor performance queries
Fix: Optimization & query rewriting.
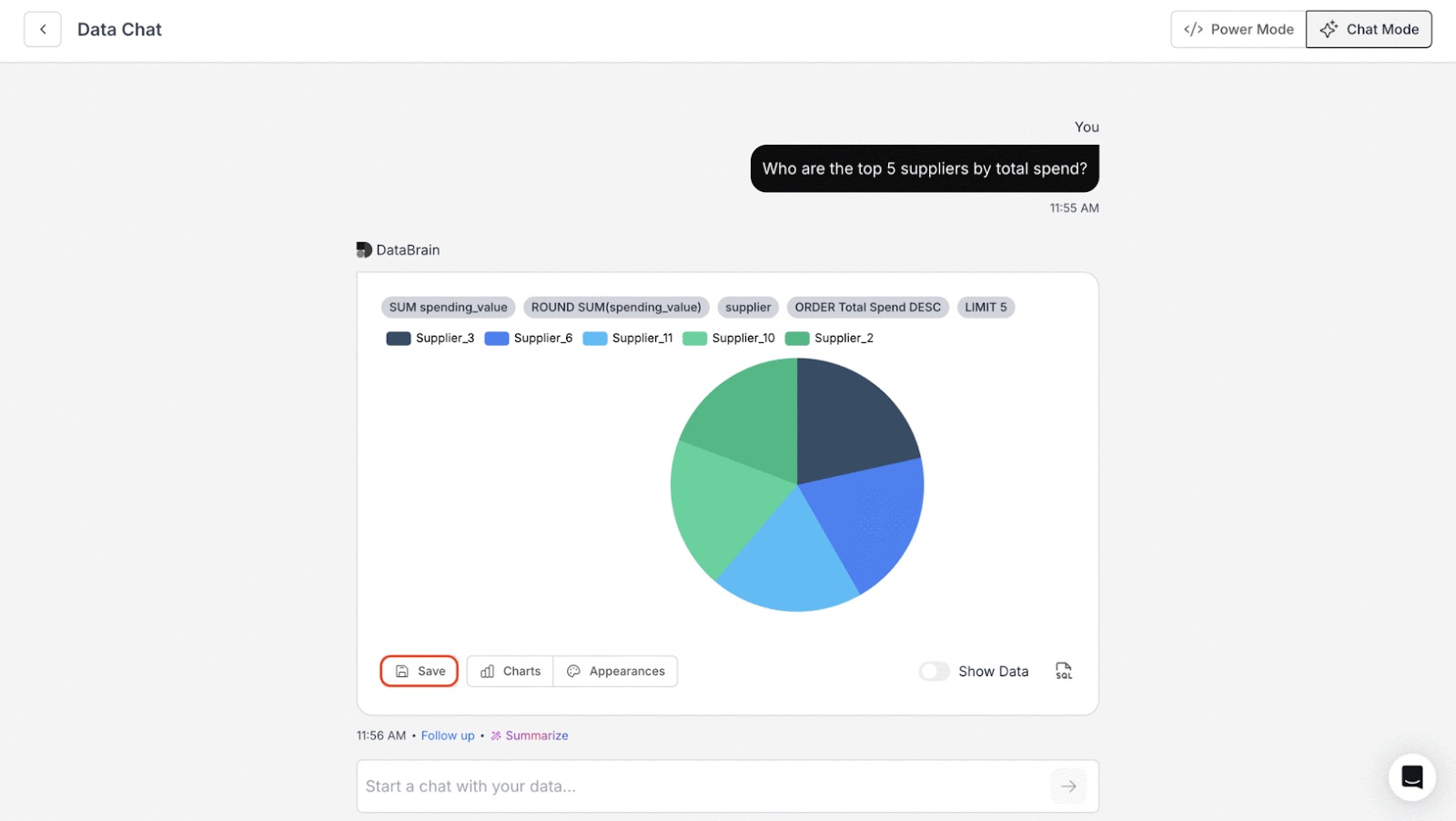
How is NLQ implemented in Databrain ?
Example question:
“Show me churned customers in Q3 by plan type.”
Databrain pipeline:
- Datamart + Semantic Layer Setup (one-time)
- Connect tables, define joins, add friendly names.
- Map business terms like churn, customer, plan type.
- Create reusable metrics if needed.
- User asks question in Chat
- “churned customers” → mapped to subscription_status = ‘churned’
- “Q3” → translated into a date filter
- “by plan type” → group by plan dimension
- SQL Auto-Generated Using Semantic Model
- Uses predefined joins (subscription → customer → plan)
- Applies filters, groups, metrics correctly
- Governance & Security Applied
- Uses existing permissions and access rules
- Result Returned
- Clean SQL + chart/table visualization
References:
This makes Databrain suitable for embedded NLQ and embedded analytics scenarios where accuracy, governance, and consistency matter.
Where NLQ Is Heading Next
Emerging innovations:
- multimodal Q&A (ask questions using charts)
- NLQ in spreadsheets
- self-improving metric definitions
- multi-source joins with zero configuration
- conversational dashboards
- reusable question memory
- “what-if” scenario NLQ
The future is not “ask anything.” The future is to constrain and guide users intelligently.
NLQ Isn’t Magic, It’s Engineering + Semantics
This is the foundation of truly trustworthy conversational analytics.
NLQ only works reliably when:
- you extract intent precisely
- you map language to entities and tables correctly
- you calculate join paths safely
- you ground SQL in semantic truth
- you validate queries before execution
Anything less produces pretty demos and terrible analytics.
If you adopt NLQ, build the pipeline properly.
You’re on the right path, move faster, define your semantics earlier, and apply NLQ only where you’ve built the foundations.


