
.png)
Why BI Requires Absolute Accuracy
Anyone who has shipped a BI feature knows this: analytics is the last place where improvisation is allowed. But improvisation is exactly how LLMs operate.
In creative workflows, being “mostly right” is acceptable.
In BI, being “almost right” is the fastest way to lose credibility.
- A $1 error in ARR sparks executive escalations.
- A slightly wrong join quietly corrupts dashboards.
- A hallucinated metric triggers unnecessary war-room conversations.
This is where teams consistently misjudge the problem. They assume a model just needs better prompting, a stronger system message, or some light fine-tuning. The truth is simpler and harsher:
LLMs aren’t failing because they’re confused. They’re failing because BI requires a level of precision they were never designed to deliver.
Unless you build guardrails around them, an LLM will produce SQL, metrics, and explanations that look polished, read confidently, and are fundamentally wrong and you usually won’t discover the mistake until it’s already influenced a decision.
Here’s a breakdown of the real limitations behind these failures, why they matter, and the architectural strategies modern analytics platforms use to prevent them.
Why BI Datasets Demand Strict Correctness
LLMs are generative models. BI requires deterministic precision. That fundamental mismatch is why things break.
In chat or creative tasks, being directionally right is fine. In BI:
- $1 error in ARR sparks immediate Slack channels.
- One wrong join produces entirely misleading dashboards.
- One hallucinated metric creates panic in leadership meetings.
BI is not linguistic. BI is math, lineage, definitions, and governed truth.
This is why analytics hallucinations are far more dangerous than hallucinations in general. They look correct. They feel correct. They are delivered confidently.
But they’re wrong and you won’t know until it’s too late.
The 5 Major Limitations of LLMs in BI
Below is a synthesis of limitations that reflect the most validated research themes on LLM limitations (reasoning instability, hallucinations, schema ignorance, ambiguous intent parsing, domain adaptation gaps) and apply them directly to BI where these weaknesses have uniquely severe consequences.
1. Ambiguous User Questions: LLMs Pretend to Understand
Users ask BI questions like humans:
- “What’s our churn last quarter?”
- “Which region performs best?”
- “Show me pipeline coverage by segment.”
But these questions hide ambiguity:
- Churn could be gross, net, revenue, logo.
- Quarter could be fiscal or calendar.
- Region could be billing address or sales territory.
Your LLM does not ask for clarification. And when it guesses wrong, the entire answer — SQL, chart, metric is incorrect. BI ambiguity is systemic. Unless the system relies on a semantic layer to ground terms, “churn” becomes whatever the model thinks churn sounds like.
Learn about Databrain’s Semantic Layer!
2. Complex Joins & Metric Definitions: Reasoning Breaks Down
LLMs are not relational engines. They don’t “understand” schemas. They pattern-match plausible SQL.
But BI queries require:
- Multi-hop joins
- Time grain alignment
- Window functions
- Slowly changing dimensions
- Metric inheritance
- Relationship pruning to avoid Cartesian explosions
When LLMs attempt these:
- They join unrelated tables
- They forget join keys
- They add non-existent columns
- They misplace a GROUP BY
- They break time-series logic
- They collapse multi-hop logic halfway through
Real BI metrics (ARR, MRR, NRR, pipeline coverage) often require 5 to 12 reasoning steps. LLM reasoning degrades significantly after step 3 or 4.
Learn how Databrain handles joins, relationships, and cardinality using a Datamart layer.
3. Lack of Schema Awareness: The Model Doesn’t Know Your Data
LLMs do not know your:
- Table names
- Business rules
- Foreign keys
- Naming conventions
- Valid join paths
They rely on probability, not truth.
This produces BI-specific hallucinations:
- Fabricated tables (“sales_pipeline_facts”)
- Invented columns (“booking_amount_usd”)
- Nonexistent metrics (“adjusted_churn_ratio”)
In NLP tasks, hallucinations are an annoyance. In BI, they break trust instantly.
Semantic layers exist because humans can’t memorize schema complexity. LLMs struggle to face even greater difficulty.
4. Hallucinated Columns, Tables, and Metrics: Because the Model Must Answer Something
This is the dark side of conversational BI.
If the database doesn’t contain a field called region_name, the model will create one.
If the schema doesn’t have renewal_flag, it will invent a proxy.
If your metric definition doesn’t match its training set expectation, it rewrites the definition.
This is not “model error”. It is how generative models are designed.
Every hallucination produces a SQL error, a query that runs but returns incorrect results. This is why guardrails must intervene before execution.
5. Inconsistent Multi-Step Reasoning: Same Question, Different Day, Different Answer
Ask the same BI question five times. You’ll often get five different SQL structures.
BI depends on:
- Repeatability
- Auditability
- Governance
- Reliable metric definitions
LLMs cannot guarantee consistency in multi-step reasoning without architectural support. This is one of the biggest reasons NLQ systems fail when built directly on top of LLMs.
How Modern Platforms Work Around These Limitations
Here’s where most teams get it wrong: They try to fix LLMs. You can’t fix a probabilistic model into becoming deterministic truth. You must build a system where the model cannot break things.
Modern BI architectures use four layers of protection.
1. Metadata & Semantic Layers: Replace Guesswork with Ground Truth
When users ask vague questions like:
“Show churn by segment last quarter”
The semantic layer resolves:
- “churn” → metric definition
- “segment” → dimension
- “last quarter” → time grain
- Tables → correct join paths
- Filters → governed definitions
LLMs don’t improvise definitions, they reference them. This eliminates 70–80% of BI hallucination patterns.
2. Schema-Aware Constraint Engines: SQL Can Only Use What Exists
Before execution, SQL is validated against:
- Allowed tables
- Allowed columns
- Allowed join paths
- Allowed metrics
- Allowed filters
If a model invents a column, the validator blocks it. If a model chooses the wrong join path, the system overrides it.
This transforms LLMs from “query authors” into “query suggestions.”
3. Prompting Constraints: Remove Creative Freedom
Freedom is the enemy of correctness.
BI prompts must be engineered to:
- Force structure
- Force metric references
- Force table whitelists
- Force standardized SQL templates
- Prevent free-text creativity
This is not optional, it’s survival.
4. Guided Analytics Workflows: When Free-Form NLQ Should Be Denied
Not all questions should be answered with NLQ.
For example:
- Cohort analysis
- Win-rate waterfall breakdowns
- Contracted ARR reconciliation
- SLA breach root-cause analysis
These require structured workflows, not open-ended chat.
A mature BI system routes users to guided flows when:
- Ambiguity is too high
- Metric logic is too complex
- Required filters exceed model reliability
- The question touches finance, risk, or compliance
This is how modern BI platforms balance flexibility with safety.
3 Questions to ask your AI Vendor
Before trusting an AI system to generate SQL or answer BI questions, ask these three non-negotiable questions.
If the vendor cannot answer “yes” to all three, the product will eventually hallucinate, misjoin tables, or redefine your metrics.
1. Do you have a real semantic layer or governed metric system?
If the system cannot map “churn,” “revenue,” or “segment” to a deterministic, governed definition, it will guess. Your BI will break the moment the LLM improvises a metric. If there is no semantic layer, there is no accuracy.
2. How do you prevent ambiguous or invalid joins?
Ask how the system ensures every query uses:
- Valid join paths
- Correct cardinality
- Approved tables
- Relationship rules
A serious vendor should guarantee:
“The model cannot generate SQL outside governed data marts or modeled relationships.”
If they say “the model is pretty accurate”, walk away.
3. Can I restrict or govern metric definitions so the model can’t invent new ones?
Your ARR, NRR, churn, and pipeline metrics must be:
- Standardized
- Version-controlled
- Immutable unless explicitly changed
- Validated against schema and lineage
If the vendor allows free-form metric creation, you will get silent metric drift, the failure in BI.
When you put these questions into practice, the pattern becomes clear: reliable AI analytics require a fundamentally different execution model.
The illustration below captures this shift from the common, unsafe approach where LLMs generate SQL directly against the warehouse, to a governed architecture where every query passes through semantic rules, validation layers, and controlled access before reaching production data.
This is the foundation any platform must have before AI answers can be trusted.
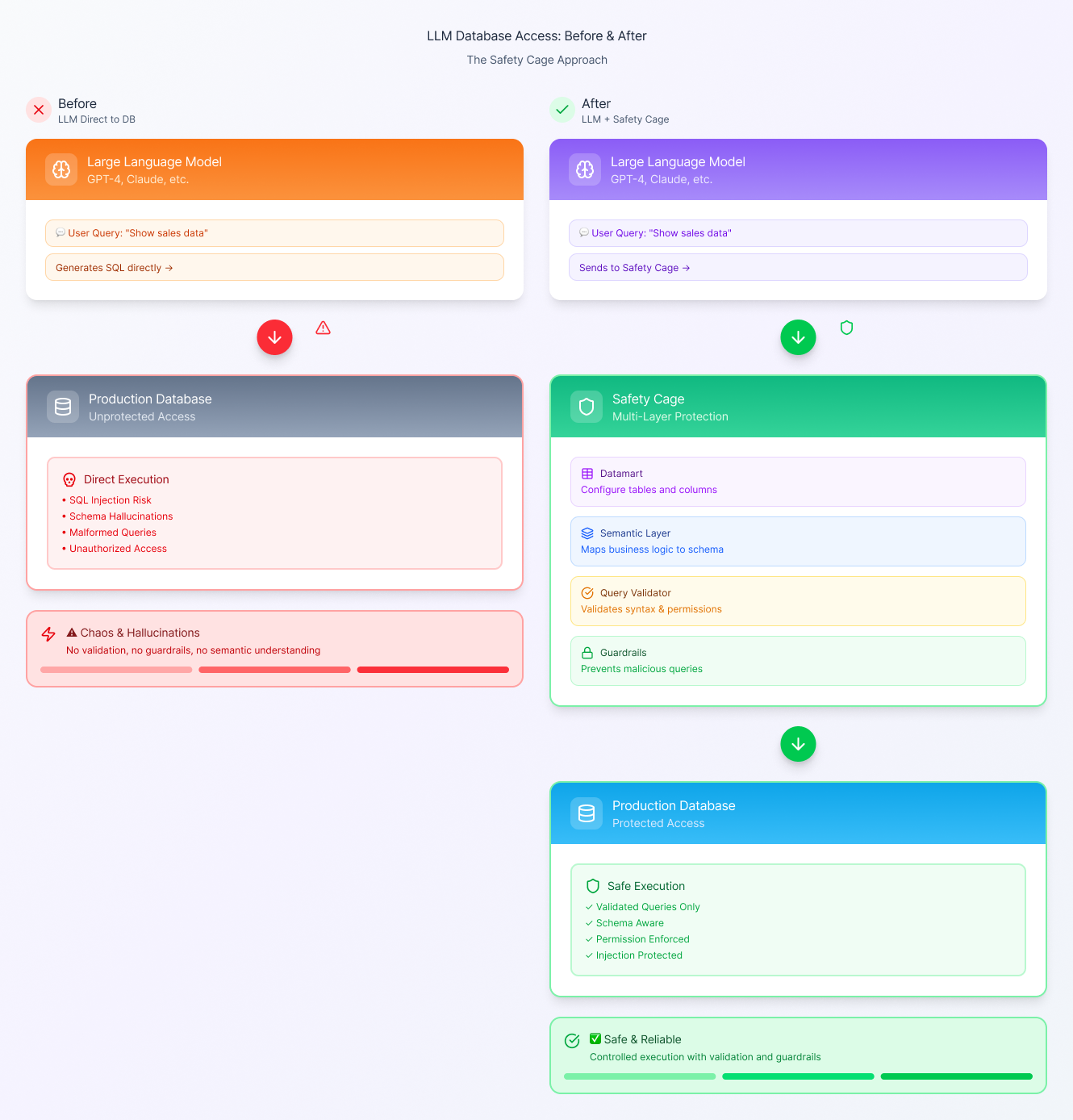
How Databrain Solves This?
1. Datamarts: A Controlled, Relationship-Aware SQL Layer
LLMs fail most often at joins, table selection, and relationship logic. Databrain solves this by forcing all generated SQL to run only against Datamarts, not the raw warehouse.
A Datamart defines:
- Which tables are available
- How they relate to each other
- Valid join paths
- Cardinality
- Allowed filters and fields
This removes 90% of schema-guessing errors because the model cannot select unknown tables or invent columns, the Datamart defines the universe.
Learn more: Datamarts for Embedded Analytics
2. Semantic Layer: No Ambiguity, No Reinvention, No Drift
Ambiguous BI terms (“churn,” “segment,” “revenue,” “active user”) are where LLMs hallucinate the most. Databrain’s Semantic Layer eliminates this entirely.
The Semantic Layer provides:
- Governed metric definitions (ARR, NRR, Pipeline, Churn)
- Dimensions with strict meaning
- Join relationships
- Metric inheritance & aggregation logic
When a user asks:
“Show churn by segment last quarter”
Databrain resolves every component deterministically:
- “churn” → mapped to the governed metric in the Semantic Layer
- “segment” → correct dimension from the model
- “last quarter” → resolved using governed fiscal rules
- Tables → inferred from the Datamart’s join conditions
- Filters → aligned with metric lineage
Learn more: Why Data Modeling & Semantic Layers matter?
3. Chat-Mode Metric Creation: Conversational
Chat Mode is conversational, but the output is strictly governed. It does three things:
a. It interprets the user’s intent.
The user can describe a metric naturally:
“Create a metric for average contract value excluding cancelled deals.”
b. Databrain validates every aspect:
- Does the column exist in the Datamart?
- Does the formula align with the semantic layer?
- Does this metric conflict with existing definitions?
- Is the calculation reproducible across dimensions and time?
Chat Mode provides convenience, but the semantic layer provides correctness.
Result:
Metric creation becomes faster and more user-friendly, without compromising governance, consistency, or semantic fidelity.
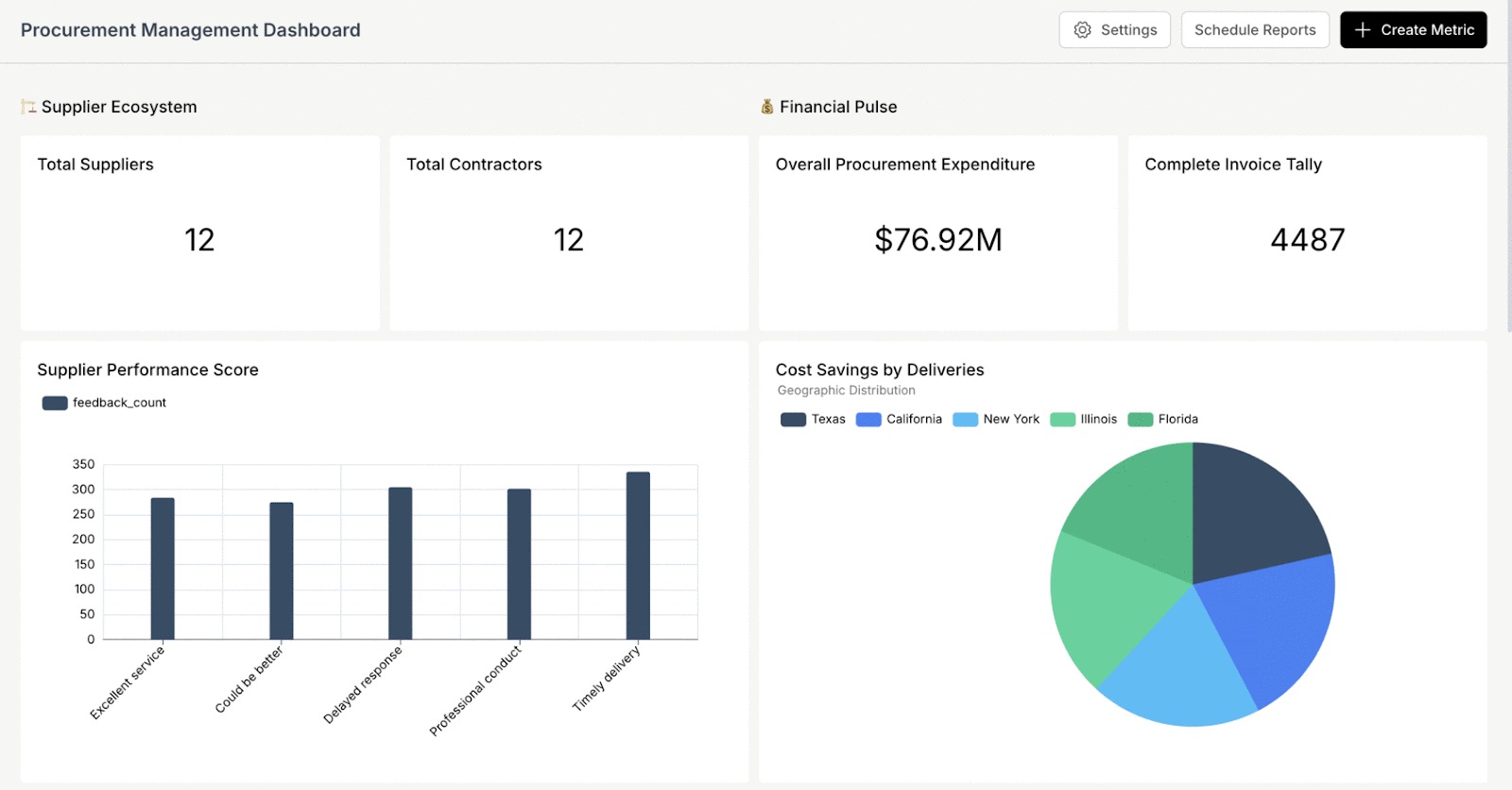
Here is a sample procurement management dashboard created using Databrain’s chat mode:
When You MUST Override the Model
There are moments when a BI platform must refuse the question.
- The question is too vague
- The metric is undefined
- The logic requires a multi-pass query
- The answer could violate data governance
- The risk of hallucination exceeds the value of automation
A safe system replies:
“This question requires clarification. Here are the available metric definitions and dimensions you can choose from.”
LLMs should behave like structured assistants with strict boundaries.
Examples of Safe Fallback Mechanisms
- Disambiguation: “Which churn definition do you want: logo, gross, or net?”
- Metric picker: Only allow governed metrics.
- Join path resolver: Pre-set mapping prevents invalid joins.
- Error recovery: Automatically reroute to templates when SQL is too complex.
- Zero-hallucination mode: Only respond using schema metadata.
This is how you convert a generative model into a trustworthy BI interface.
The Hard Truth: If You Skip Guardrails, NLQ Will Fail
Organizations often overestimate what LLMs can do and underestimate how fragile SQL generation is.
If you rely solely on the model:
- Hallucinations will ship
- Users will lose trust
- Adoption will collapse
- Leaders will insist on audits
- You will eventually rebuild with guardrails
Skipping guardrails doesn’t save time, it guarantees failure. Teams succeeding with NLQ aren’t “prompting better”. They’re architecting better.
LLMs Are Powerful, But Only Inside a Safety Cage
LLMs are not the problem. The environment around them is.
With:
- Semantic layers
- Metadata
- Schema constraints
- Guided workflows
- Structured prompting
LLMs move from dangerously confident to reliably accurate.
If you’re building NLQ without these layers, you’re not building a product, you’re building a liability. Fix the foundation and you can unlock the future of conversational analytics that teams actually trust.
To see how modern platforms overcome these LLM limitations in practice, explore our embedded analytics guide.


